


Introduction:
Supervised Machine Learning might sound like a complex concept, but at its core, it's all about making predictions or classifications based on existing data. Imagine having a teacher guide you through the process of learning – that's exactly what happens in supervised learning. Let's break down the basics in simple language.
Understanding the Basics:
In supervised learning, we have input variables (x) and an output variable (Y). The goal is to teach an algorithm to learn the relationship between these inputs and outputs. It's like a teacher correcting your homework – the algorithm makes predictions, and the teacher corrects them until the algorithm gets it right.
Supervised learning is where you have input variables (x) and an output variable (Y) and you use an algorithm to learn the mapping function from the input to the output. Y = f(X)
How it Works:
First, we gather a bunch of labeled data, where inputs are paired with correct outputs. The algorithm then learns from this dataset to create a model. This model can make predictions for new, unseen data. The more practice data it has, the better it becomes at making accurate predictions.
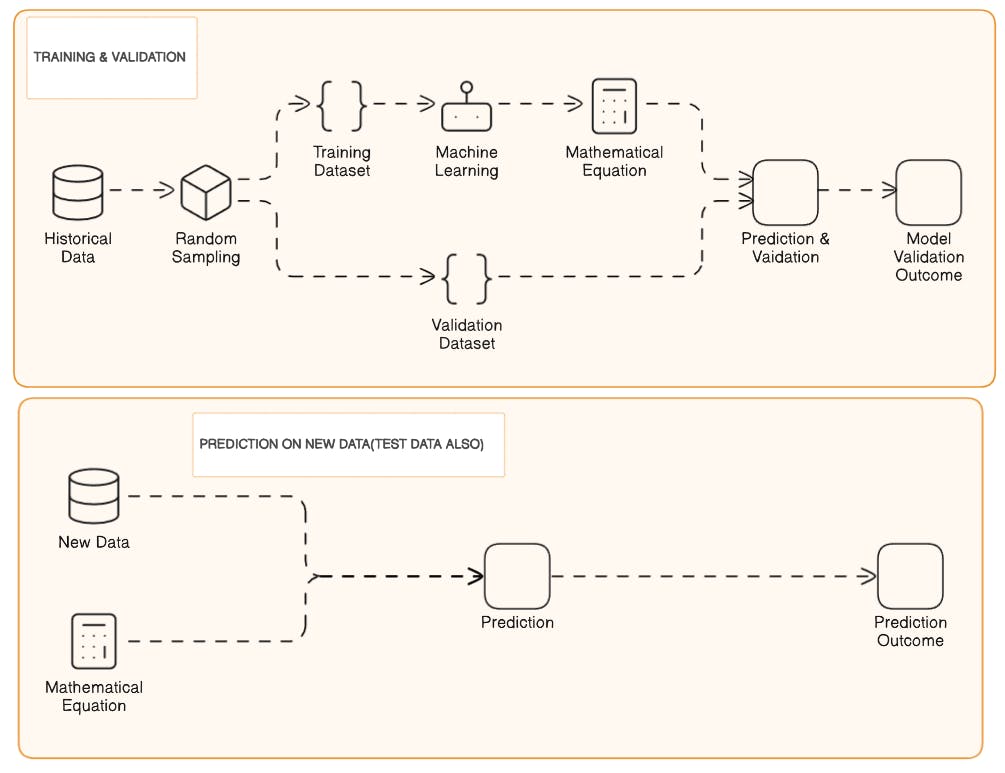
Classification vs. Regression:
Classification: Think of this as sorting data into categories. For example, telling the difference between cats and dogs in pictures. Common algorithms include decision trees, random forests, and support vector machines.
Regression: Here, the algorithm finds relationships between variables for continuous data. It's like predicting the price of a house based on various features. Linear regression and logistic regression are examples of regression algorithms.
Advantages of Supervised Learning:
Clear Goal: The algorithm knows what it's aiming for right from the start.
Specific Categories: You can define precise categories, making it straightforward.
Easy to Understand: Among various machine learning types, supervised learning is relatively easy to grasp.
No Ongoing Training: Once trained, the model doesn't need continuous training – it just applies what it learned.
Disadvantages:
Need for Large Datasets: Good results often require a substantial amount of training data.
Labeled Data: The data needs to be labeled for the algorithm to work correctly.
Simplicity Limitation: Not suitable for complex tasks due to its straightforward nature.
Applications in Everyday Life:
Text and Image Classification: Sorting emails as spam or not, identifying objects in pictures.
Healthcare: Detecting tumors and predicting disease risks.
Predictive Maintenance: Forecasting when equipment might need repairs.
Financial Predictions: Anticipating stock market trends or house prices.
Customer Sentiment Analysis: Understanding how customers feel about a product or service.