


Unsupervised learning, a fascinating realm within the world of machine learning, empowers algorithms to uncover hidden patterns and structures lurking within unlabeled datasets. In this blog, we embark on an enlightening journey to explore the workings of unsupervised learning, its diverse applications, and the challenges it presents.
Unsupervised Machine Learning
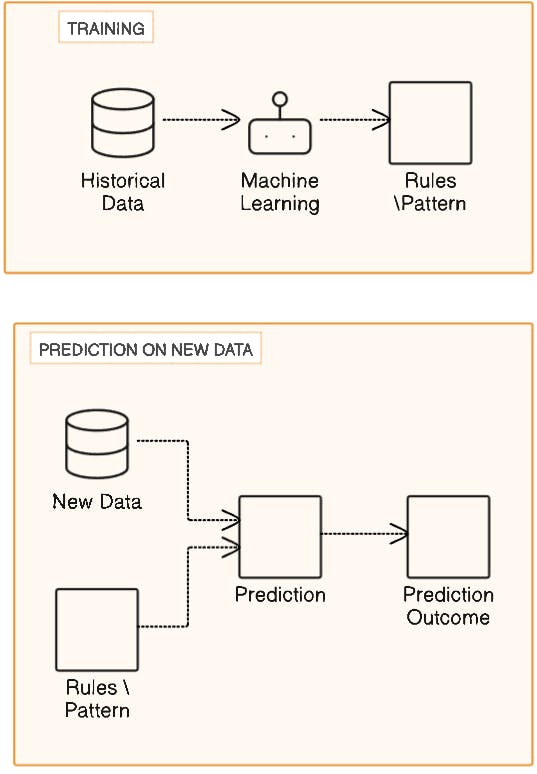
Unsupervised learning is a type of machine learning where algorithms learn from data without being told what the correct answers are. Unlike supervised learning, where data has labels or known outcomes, unsupervised learning deals with data that isn't labeled. This means the algorithm tries to figure out patterns or similarities in the data by itself.
The main goal of unsupervised learning is to explore and understand the structure of the data. It does this by finding patterns, relationships, or groups in the data without any hints or instructions. Unsupervised learning uses techniques like clustering, reducing the number of features, and spotting anomalies to achieve this.
Important Uses of Unsupervised Learning
Unsupervised learning plays a crucial role in various domains and applications due to its ability to extract patterns and structures from unlabeled data. Some important uses of unsupervised learning include:
Clustering: Unsupervised learning algorithms like k-means, hierarchical clustering, and DBSCAN are widely used for grouping similar data points together based on their features. Clustering finds applications in customer segmentation, document clustering, image segmentation, and anomaly detection.
Dimensionality Reduction: Techniques such as Principal Component Analysis (PCA), t-distributed Stochastic Neighbor Embedding (t-SNE), and autoencoders help reduce the dimensionality of data while preserving its essential information. Dimensionality reduction is useful for visualization, feature selection, and speeding up subsequent supervised learning tasks.
Anomaly Detection: Unsupervised learning algorithms can identify outliers or anomalies in data that deviate significantly from the norm. This is crucial in various fields including fraud detection in financial transactions, network security, and predictive maintenance in manufacturing.
Density Estimation: Density estimation methods like Gaussian Mixture Models (GMMs) and kernel density estimation help model the underlying probability distribution of data. This is useful for anomaly detection, outlier removal, and generative modeling tasks.
Generative Modeling: Unsupervised learning techniques enable the creation of generative models that can learn the underlying structure of data and generate new samples similar to the training data. Generative models like Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) find applications in image synthesis, text generation, and data augmentation.
Market Basket Analysis: Unsupervised learning algorithms can analyze transactional data to discover patterns and associations between different items purchased together. Market basket analysis is widely used in retail for product recommendation, inventory management, and marketing strategies.
Natural Language Processing (NLP): Unsupervised learning techniques are employed in various NLP tasks such as topic modeling, word embeddings, and document clustering. These methods help extract meaningful representations from text data without requiring labeled examples.
Image and Signal Processing: Unsupervised learning algorithms are utilized in tasks such as image segmentation, denoising, and compression. They help identify patterns and structures in images, audio signals, and other types of data without the need for explicit supervision.
How Unsupervised Learning Works
Unsupervised learning works by extracting patterns, structures, or representations from unlabeled data without explicit guidance or supervision. It explores the inherent structure of the data and finds relationships among data points. Let's consider a simple example to illustrate how unsupervised learning works:
Example: Clustering of Customer Data
Imagine you have a dataset containing information about customers from an online retail store. Each data point represents a customer, and the features include demographic information like age, gender, income, and purchasing behavior such as the types of products purchased, frequency of purchases, and average purchase amount.
Without labels or specific guidance, you can apply unsupervised learning algorithms, such as k-means clustering, to group similar customers together based on their characteristics.
Here's how the process unfolds:
Data Preprocessing: Clean the data by handling missing values, scaling numerical features, and encoding categorical variables if necessary.
Choosing an Algorithm: Select an appropriate unsupervised learning algorithm for the task at hand. In this case, we choose k-means clustering because we want to partition customers into distinct groups based on their attributes.
Model Training: Apply the k-means algorithm to the preprocessed data. The algorithm iteratively assigns each data point to the nearest cluster centroid and updates the centroids until convergence.
Cluster Interpretation: Once the algorithm converges, examine the resulting clusters to understand the characteristics of each group. You might find clusters representing different customer segments, such as:
High-income, frequent shoppers
Young, budget-conscious shoppers
Middle-aged, occasional buyers
Elderly, high-value customers
Evaluation (if applicable): In unsupervised learning, there's typically no ground truth labels to evaluate the performance of the model. Instead, evaluation may involve assessing the coherence and interpretability of the clusters obtained.
Use Case Applications: Use the identified customer segments for targeted marketing campaigns, personalized recommendations, or product assortment strategies. For example, you could tailor promotional offers based on the preferences and behavior of each customer segment.
In this example, unsupervised learning enables the discovery of meaningful patterns and segments within the customer data without the need for labeled examples. It helps businesses gain insights into customer behavior, preferences, and segmentation, which can inform strategic decision-making and improve customer satisfaction and retention.
Unsupervised Machine Learning Methods
Here are some common unsupervised learning methods:
Clustering Algorithms:
K-Means: A partitioning algorithm that divides data into 'k' clusters based on similarity.
Hierarchical Clustering: Builds a tree of clusters by recursively merging or splitting them based on their similarity.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Clusters data points based on their density in the feature space.
Mean Shift: A non-parametric clustering algorithm that finds modes or peaks in the density distribution of data points.
Dimensionality Reduction Techniques:
Principal Component Analysis (PCA): Projects data onto a lower-dimensional space while preserving as much variance as possible.
t-Distributed Stochastic Neighbor Embedding (t-SNE): Reduces dimensionality for visualization by preserving local structures and similarities.
Autoencoders: Neural network models that learn to encode data into a lower-dimensional representation and then decode it back to the original input. The latent space captures important features of the data.
Anomaly Detection Methods:
One-Class SVM (Support Vector Machine): Trains a model on normal data points and identifies anomalies as data points that fall outside the learned boundaries.
Isolation Forest: Builds an ensemble of decision trees to isolate anomalies in the data by isolating them in fewer steps compared to normal data points.
Density Estimation Techniques:
Gaussian Mixture Models (GMMs): Model the probability distribution of the data as a mixture of multiple Gaussian distributions.
Kernel Density Estimation (KDE): Estimates the probability density function of the data based on kernel functions centered around data points.
Generative Models:
Variational Autoencoders (VAEs): Variational inference methods that learn to generate data by modeling the latent space distribution of input data.
Generative Adversarial Networks (GANs): Consist of a generator and a discriminator network that compete against each other. The generator learns to produce realistic data samples while the discriminator learns to distinguish between real and generated samples.
Association Rule Learning:
- Apriori Algorithm: Discovers frequent itemsets in transactional databases and extracts association rules among items based on their co-occurrence.
These unsupervised learning methods find applications in various domains such as data mining, pattern recognition, anomaly detection, clustering, and exploratory data analysis. They are particularly useful when labeled data is scarce or expensive to obtain, and they help uncover hidden patterns and structures within datasets.
Real-world Unsupervised Learning Examples
Unsupervised learning finds numerous real-world applications across various domains. Here are some examples:
Market Segmentation: Businesses use unsupervised learning techniques like clustering to segment their customer base based on purchasing behavior, demographics, and preferences. This helps tailor marketing strategies, product offerings, and customer service to different segments.
Anomaly Detection in Cybersecurity: Unsupervised learning algorithms are used to detect unusual patterns in network traffic, system logs, and user behavior that may indicate security breaches or anomalous activities. Techniques such as clustering and density estimation help identify outliers and anomalies in large datasets.
Medical Image Analysis: Unsupervised learning methods are applied in medical imaging to segment organs, tumors, and anomalies from MRI, CT, and ultrasound scans. Clustering and dimensionality reduction techniques help identify patterns and structures in medical images, aiding diagnosis and treatment planning.
Natural Language Processing (NLP): Unsupervised learning algorithms like word embeddings and topic modeling are used to analyze and extract insights from large text corpora. Word embeddings represent words in a continuous vector space, capturing semantic relationships, while topic modeling algorithms like Latent Dirichlet Allocation (LDA) identify latent topics in text documents.
Recommendation Systems: Unsupervised learning techniques are employed in recommendation systems to analyze user preferences and suggest relevant products, movies, or content. Collaborative filtering algorithms leverage user-item interaction data to identify similarities between users and items, enabling personalized recommendations.
Genomics and Bioinformatics: Unsupervised learning methods are utilized in genomics to analyze DNA sequences, identify gene expression patterns, and classify genetic variants. Clustering algorithms help identify groups of genes with similar expression profiles, facilitating the discovery of gene functions and pathways.
Financial Fraud Detection: Unsupervised learning algorithms are applied in finance to detect fraudulent transactions, money laundering activities, and credit card fraud. Anomaly detection techniques help identify unusual patterns in transaction data, such as unexpected spikes in transaction volume or unusual spending behavior.
Environmental Monitoring: Unsupervised learning methods are used in environmental science to analyze remote sensing data, satellite imagery, and sensor data for monitoring land use, deforestation, urbanization, and climate change. Clustering and classification algorithms help identify environmental patterns and trends from large-scale datasets.
These examples illustrate the diverse applications of unsupervised learning across various fields, enabling data-driven insights, pattern discovery, and decision-making from unlabeled data.
Challenges of Unsupervised Learning
Computational Complexity: Handling large volumes of training data can lead to increased computational complexity.
Longer Training Times: Unsupervised learning algorithms often require more time to train compared to supervised learning methods.
Higher Risk of Inaccurate Results: Without labeled data to guide the learning process, unsupervised algorithms may produce inaccurate or unreliable results.
Human Intervention for Validation: In many cases, human intervention is necessary to validate the output variables generated by unsupervised learning algorithms.
Lack of Transparency: Unsupervised learning algorithms may lack transparency regarding the basis on which data was clustered or grouped.
Addressing these challenges requires careful consideration of algorithm selection, parameter tuning, and evaluation techniques. Additionally, domain expertise and human oversight play crucial roles in validating and interpreting the results of unsupervised learning algorithms, ensuring that the insights derived from these methods are meaningful and actionable. Despite these challenges, unsupervised learning remains a powerful tool for exploring and uncovering hidden patterns within complex datasets, offering valuable insights for various applications across diverse domains.